Як налаштувати проксі в Scraper API
Scraper API - це професійний інструмент для скрапінгу веб-сайтів. Веб-скрапер дасть змогу вирішити безліч завдань для ефективного ведення бізнесу. Він допоможе швидко витягти дані з необхідного ресурсу і представити в зручному для подальшого аналізу форматі.
Це може бути пошук SEO-оптимізованих описів товарів із сайтів конкурентів, моніторинг цін на товари в інтернет-магазинах, збір статистики активності (лайки, репости, перегляди) відвідувачів, відстеження останніх новин на інформаційному порталі. Однак сайти блокують IP-адреси, за якими було виявлено веб-скрапінг даних, тому для стабільної роботи потрібно налаштувати проксі для Scraper API.
Покрокове налаштування проксі в Scraper API
Для налаштування проксі для скрапінгу Scraper API виконайте такі дії:
- Створіть акаунт на ресурсі ScraperAPI і на головній сторінці в категорії "Dashboard" знайдіть поле "Sample Proxy Code".
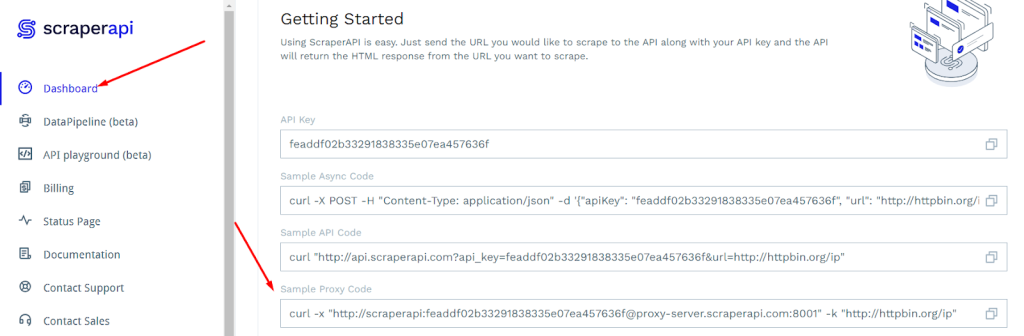
- У полі "Sample Proxy Code" міститься код такого виду:
curl -x "http://scraperapi:APIKEY@proxy-server.scraperapi.com:8001" -k "http://httpbin.org/ip" - Скопіюйте його і вставте в скрипт. Внесіть такі зміни в код:
замість "scraperapi" введіть свій логін від приватного проксі;
замість "APIKEY" - пароль;
замість "proxy-server.scraperapi.com" - свою нову IP-адресу;
через двокрапку - порт;
після "-k" у лапках потрібно вказати адресу сторінки, з якої потрібно зібрати дані.
У підсумку, має вийти так:
curl -x "http://LOGIN:PASSWORD@IP-ADRESS:8001" -k "http://httpbin.org/ip"
Використовувати команду "http://scraperapi:APIKEY@proxy-server.scraperapi.com:8001" можна для різних мов програмування, залежно від чого код може видозмінюватися. Наприклад, для Python приклад запиту матиме такий вигляд:
import requests
proxies = {
"http": "http://scraperapi:APIKEY@proxy-server.scraperapi.com:8001"
}
r = requests.get('http://httpbin.org/ip', proxies=proxies, verify=False)
print(r.text)
# Scrapy users can likewise simply pass their API key in headers.
# NB: Scrapy skips SSL verification by default.
# ...other scrapy setup code
start_urls = ['http://httpbin.org/ip']
meta = {
"proxy": "http://scraperapi:APIKEY@proxy-server.scraperapi.com:8001"
}
def parse(self, response):
# ...your parsing logic here
yield scrapy.Request(url, callback=self.parse, headers=headers, meta=meta)
Для Ruby так:
require 'httparty'
HTTParty::Basement.default_options.update(verify: false)
response = HTTParty.get('http://httpbin.org/ip', {
http_proxyaddr: "proxy-server.scraperapi.com",
http_proxyport: "8001",
http_proxyuser: "scraperapi",
http_proxypass: "APIKEY"
})
results = response.body
puts results
Для NodeJS так:
const axios = require('axios');
axios.get('http://httpbin.org/ip', {
method: 'GET',
proxy: {
host: 'proxy-server.scraperapi.com',
port: 8001,
auth: {
username: 'scraperapi',
password: 'APIKEY'
},
protocol: 'http'
}
})
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
});
Після налаштування проксі ви зможете відправляти запити на сайти з різних IP, завдяки чому знижується ризик блокування за IP. Також це дасть змогу робити запити на ті ресурси, які заблоковані за гео.